알고리즘이라는 것은 원하는 출력 또는 결과를 얻기 위해서 명령어 셋을 특정 순서에 따라 정의해놓은 것입니다. 간단히 말하면 수학의 공식과도 같은 것이죠.
데이터 구조 관점에서 봤을 때 몇가지 중요한 알고리즘 카테고리를 살펴보면 아래와 같습니다 −
검색 알고리즘 − 데이터 구조 안에 있는 특정 아이템을 찾기 위한 알고리즘
정렬 알고리즘 − 아이템들을 특정 순서에 따라 정렬하기 위한 알고리즘
삽입 알고리즘 − 데이터 구조에 아이템을 추가하기 위한 알고리즘
수정 알고리즘 − 데이터 구조에 이미 존재하는 아이템을 수정하기 위한 알고리즘
삭제 알고리즘 − 데이터 구조에 이미 존재하는 아이템을 삭제하기 위한 알고리즘
알고리즘의 특징
알고리즘을 다음과 같은 특징을 가지고 있습니다 −
명확성 − 알고리즘은 애매모호하지 않고 명확해야 합니다.
Input − 알고리즘은 0개 이상의 잘 정의된 입력값이 있어야 합니다.
Output − 알고리즘은 하나 이상의 잘 정의된 출력값이 있어야 하며 원하는 결과와 매치되어야 합니다.
유한성 − 알고리즘은 유한한 단계를 거친 후 종료되어야 합니다.
실현가능성 − 알고리즘은 실행할 수 있어야 합니다
독립성 − 알고리즘의 각각의 단계는 어떤 프로그래밍 코드와도 독립적이어야 합니다.
알고리즘을 어떻게 작성하나요?
알고리즘을 작성하는 방법이 딱히 정해져 있지는 않습니다. 단지, 알고리즘이라는 것은 어떤 문제를 위한 알고리즘인지, 리소스는 어떤 것들인지에 의존적입니다. 또한 프로그래밍 언어에 따라 알고리즘의 단계가 바뀌거나 하면 그것은 알고리즘이라고 할 수 없습니다. 알고리즘이란 프로그래밍 언어에 독립적이어야 하니까요. 간단한 알고리즘은 모든 프로그래밍 언어에서 제공하는 루프문이나 조건문을 이용해서 만들 수 있습니다.
가장 중요한 것은, 알고리즘을 작성하기 위해서는 어떤 문제를 풀기위한 것인지부터 명확해야 한다는 것입니다.
예제
문제 − 두 숫자를 더해서 출력하는 알고리즘을 만들어보세요.
step 1 − 시작 step 2 − 3개의 정수 정의 a, b, c step 3 − a 와 b 의 정수값 정의 step 4 − a 와 b 의 정수값을 더한다 step 5 − c 에 step 4의 결과를 저장한다. step 6 − c 에 저장된 값을 출력한다. step 7 − 종료
알고리즘은 프로그래머에게 어떻게 코드를 작성해야 하는 지를 말해줍니다. 알고리즘은 아래처럼 작성할 수도 있습니다 −
step 1 − 덧셈 시작 step 2 − a 와 b 의 값을 읽어온다. step 3 − c ← a + b step 4 − c 출력 step 5 − 종료
알고리즘 디자인과 분석에는 보통 아래쪽에 쓰여진 방법을 많이 사용합니다. 더 깔끔하고 가독성이 높기 때문이죠.
우리는 어떤 문제가 주어졌을 때 알고리즘을 디자인합니다. 그리고 그 문제는 여러 방법에 의해 해결될 수 있습니다.
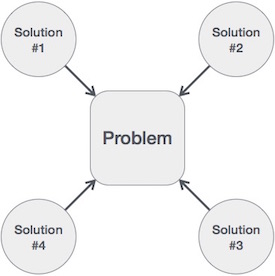
즉, 하나의 문제를 풀기위해서 여러개의 알고리즘이 작성될 수 있죠. 그래서 그 알고리즘들 중에서 어떤 것이 최선인지를 분별해야 하는 능력을 길러야 합니다.
알고리즘 분석
알고리즘의 효율성은 구현하기 전과 후에 분석될 수 있습니다.
구현 전 분석 − 구현 전 분석은 알고리즘을 이론적으로 분석하는 것입니다. 이 경우 프로세서의 속도와 같은 모든 다른 요인들은 알고리즘 실행에 아무런 영향을 미치지 않는다고 가정하고 분석을 하게됩니다.
구현 후 분석 − 이 분석은 경험적 분석이라고도 합니다. 실제로 알고리즘을 프로그래밍 언어로 구현하고 컴퓨터에서 실행시켜서 얻은 결과로 분석을 하기 때문에 실질적으로 도움이 되는 결과를 얻을 수 있습니다.
우선 구현 전 분석에 대해서 알아볼텐데요, 알고리즘 분석은 실행시간을 주로 분석하게 되는데 이때 이 실행시간이라는 것은 실제로 몇 초, 몇 분 걸렸다 라기 보다는 몇 개의 명령어가 실행이 된 뒤에 종료가 되는지를 분석하는 것입니다.
알고리즘 복잡도
n개의 입력값을 받는 알고리즘 X 가 있다고 가정해봅시다. 이때 X의 효율성을 결정짓는 주 요인 두가지는 바로 시간과 공간입니다.
시간 요인 − 시간은 중요한 명령어들이 몇개나 실행이 되는지를 의미합니다.
공간 요인 − 공간은 알고리즘을 실행하기 위한 최대 메모리 사용량을 수치로 잰 것입니다.
공간 복잡도
알고리즘의 공간 복잡도는 알고리즘 실행에 필요한 메모리 공간이 얼마나 많은지를 의미합니다. 알고리즘에 의해 필요한 공간은 다음 두가지 요인의 합과 같습니다. −
문제의 크기가 얼마나 크냐와는 관계없이 알고리즘이 필요로하는 필수 고정 공간. 예를 들면, 알고리즘에서 사용되는 상수나 변수의 사이즈 등.
문제의 크기에 따라 사이즈가 변하는 가변 공간. 예를 들면, 동적 메모리 할당이나 재귀 스택 공간 등
알고리즘 P의 공간 복잡도 S(P) = C + SP(I) 입니다. 여기서 C 는 고정 부분이고 S(I) 가 가변 부분입니다. I는 인스턴스의 특징을 의미합니다. 개념을 좀 더 이해하기 쉽게 아래 예제를 함께 보겠습니다 −
알고리즘: SUM(A, B) Step 1 - 시작 Step 2 - C ← A + B + 10 Step 3 - 종료
여기 A, B 그리고 C 세개의 변수와 하나의 상수가 있습니다. 즉, S(P) = 1+3 입니다.
시간 복잡도
시간 복잡도는 알고리즘이 실행되고 종료되기 까지 얼마나 많은 시간이 걸리는지에 대한 표현 수단입니다. 시간 요건은 T(n)으로 표현 할 수 있는데 여기서 T(n) 은 각 단계가 상수 시간을 소모한다고 했을 때 알고리즘이 필요로 하는 총 단계의 개수입니다.
예를 들면, 두 개의 n 비트 정수의 덧셈을 할 때 n 단계를 거치게 됩니다. 결국, 총 소요시간은 T(n) = (두 개의 비트를 합하는데 소요되는 시간)*n 입니다. 여기서 우리는 T(n) 이 입력 데이터 사이즈에 따라 선형적으로 증가함을 알 수 있습니다.
시간 복잡도를 표현하는 방법도 여러가지가 있습니다. O 노테이션, Ω 노테이션, 그리고 θ 노테이션이 있습니다.
O 노테이션을 가장 많이 사용하는데요, O 노테이션은 알고리즘을 실행함에 있어서 최악의 소요시간을 표시하는 방법입니다.
이와는 반대로 Ω 노테이션은 최소 소요시간을 표시하는 방법이고요, θ 노테이션은 최소, 최대 소요시간을 표시하는 방법입니다.
'🆕 정보통' 카테고리의 다른 글
| 보간 탐색 ( Interpolation Search ) (0) | 2016.06.25 |
|---|---|
| 이진 탐색 알고리즘 ( Binary Search Algorithm ) (0) | 2016.06.25 |
| 선형(순차) 탐색 알고리즘 (0) | 2016.06.25 |
| Divide and Conquer ( 분할 정복 알고리즘 ) (0) | 2016.06.24 |
| Greedy Algorithm (그리디 알고리즘) (0) | 2016.06.24 |



댓글